
■前回の記事
Splunkへのデータの取り込み方法を紹介しました。
■今回の記事
前回取り込んだデータには、「タイムスタンプ」と「ツイート本文」の2種類しか属性がありませんでした。
今回は「ツイートのポジネガ極性」という属性を加えたデータを使用します。
今回取り込むデータは下記のようなフォーマットになっています。
[タイムスタンプ]\t[ツイート本文]\tPN_Type=[ポジネガ極性]

ツイートのポジネガ極性は、下記の単語辞書などを使用して、付けたものです。
(こちらの内容についてはまた別の記事で紹介したいと思います)
PN Table
http://www.lr.pi.titech.ac.jp/~takamura/pndic_ja.html
前回の記事と同様に、「データの入力」からtxtファイルを読み込みます。
下記コマンドで検索します。
source="*PN*"

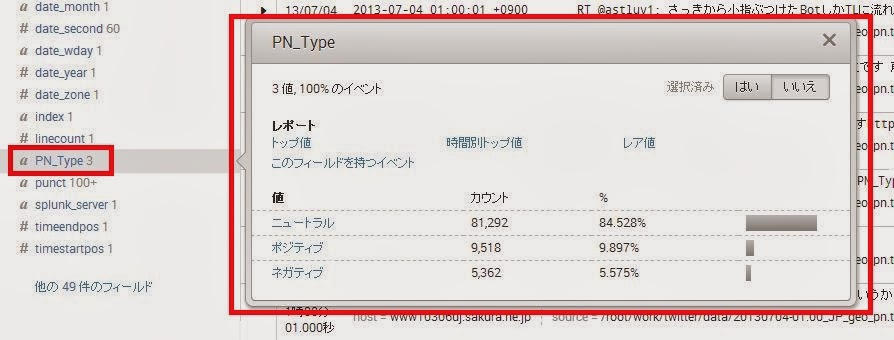
出てきた検索結果の一つを選択してみると、上記のように"PN_Type"というフィールドとその値が認識されていることがわかります。
splunkは、データの中に フィールド名=[値] という表記があると、自動的にフィールドを設定し、抽出してくれるようになっています。
次はポジネガの推移を時系列でみてみます。
下記コマンドを検索バーに入力します。
source="*PN*" | timechart count by PN_Type
すると、下記のような結果が出てきます。

「視覚エフェクト」タブを選択してみます。


このようにして、グラフで結果が確認できるので便利です。
グラフのタイプも色々あります。
今回はSplunkの機能の紹介が目的だったため、
特別、分析のようなことはしませんでしたが、他の属性データをデータに含めたり、
商品名などで検索したりすると、何か傾向のようなものがつかめてくるかもしれません。

0 件のコメント:
コメントを投稿
注: コメントを投稿できるのは、このブログのメンバーだけです。